What Specifying MonadBFT Taught Us About Quint

In this post, we describe how we used Quint to analyze the MonadBFT consensus protocol. We took the paper as our input artifact and worked through it systematically: we formally specified the definitions and pseudo code, validated the lemmas and theorems through simulation, and reproduced the scenario diagrams as executable runs. The main takeaway for Category Labs was that we didn’t find any problems in the designed protocol: During our analysis we surfaced a number of ambiguities in definitions, which demonstrated that, in principle, our modeling and Quint was adequate to find subtle issues. That in this process we didn’t find problems in the protocol increased the confidence in its correctness. The main takeaway for Quint practitioners is a set of techniques for making large, complex specifications tractable, which we summarize at the end of this post.
Quint is a natural fit for distributed BFT consensus protocols. In these protocols, the state space and message histories grow with the number of participants, timing is non-deterministic, and a subset of participants may behave arbitrarily. Quint operates at a high enough level of abstraction to model protocol logic without getting tangled in implementation details. Non-determinism is first-class, which makes modeling faults and network behavior straightforward. The simulator explores the state space and finds subtle bugs. Runs serve as executable documentation: you can show a specific execution to a non-specialist and have them follow the protocol step by step. We have said this in previous posts, and have proved all of this to ourselves, e.g., by working on the original Malachite, and most recently during the Malachite 5f refactor. But then comes MonadBFT.
We first encountered MonadBFT while developing Choreo, and the protocol left an impression. Unlike simpler BFT protocols, where most of the business logic reduces to counting votes and timing out rounds, MonadBFT has additional requirements, like no-tail-forking, which ensures that proposals by honest leaders are not abandoned. While providing stronger security guarantees for the protocol, these mechanisms require keeping track of past proposals and votes, increasing the state space and making reasoning about the protocol, whether automated or by a human, harder.
To give a rough idea of the complexity involved: the signed message algorithm in the celebrated “The Byzantine Generals Problem” paper takes 13 lines of pseudo code, while MonadBFT’s pseudo code takes about 7 pages. Having written papers on consensus ourselves, we understand how hard it is to keep pseudo code internally consistent (making sure functions are called with the right names and parameters), get the mathematical definitions right, state lemmas unambiguously and write solid pen-and-paper proofs. So we were not surprised that the people at Category Labs, the team that developed MonadBFT, wanted an independent review of their work and their protocol.
Consensus algorithms are close to our hearts, and we are happy when we get the opportunity to work on one. At the same time, from our work on Choreo we understood that MonadBFT would push Quint and its users out of their comfort zone. For instance, we often say that Quint is great because the simulator gives you traces you can inspect. But if a trace is a sequence of 100 states and each state takes about 7 screen pages to view, inspection becomes less fun. And indeed, as we discuss below, the project motivated some improvements to the Quint tooling in recent releases, including the out-of-the-box parallel Rust simulator and improved error messages for runtime errors.
What were the outcomes?
For Category Labs, the Quint model and the analysis results gave them more confidence in their protocol. We did not provide a formal proof, but validated the lemmas, theorems, and example scenarios from the paper through extensive simulation and writing runs. Doing so required several minor fixes in the pseudo code and clarifications in definitions and lemma statements. This showed that formal specification and analysis in Quint actually is able to find problematic cases. This also confirmed that the Category Labs team’s work was thorough and no fundamental issues were found in the protocol design. However, they left several behaviors unclear or unspecified (e.g., what happens precisely if several blocks are committed at once) that may also lead to challenges/gaps in the implementation, so they used our feedback internally to align the implementation to the protocol.
For us, we sharpened our tools: both the core tool itself and our approaches to analyzing complex systems, including abstractions, reductions, useful displayers, and modeling faults. Below, we discuss key techniques to tame the Monad model, but let’s first discuss in a bit more detail why MonadBFT is a challenge for (manual and automated) analysis in general, and for Quint in special.
Challenges in reasoning about MonadBFT
Let’s start with a quick overview on the features in which MonadBFT deviates from other consensus (or more precisely state machine replication) protocols. MonadBFT has a protection against MEV attacks, which is called no-tail forking. The idea is that once a block proposed by a leader can gather a lot of support, that is, a big majority voted for it (which can be proven by a quorum certificate QC), it cannot be abandoned, unless the leader provably equivocates.
To achieve this, MonadBFT introduces a reproposal mechanism, where a leader recovering from a failed view must repropose the block from that view instead of proposing a new one. A view fails if it timeouts, which means a quorum of processes send timeout messages. To ensure that no QC can be abandoned, timeouts are not just signaling that a timer expired but also convey data to prove what the validator has voted on and what QCs it has seen. This data must be combined, verified, checked, etc. and storing and transmitting the required data for these verification adds a lot of complexity.
Fast recovery is a recent extension to the protocol that speeds up the most common fault scenario: a single faulty proposer followed by correct ones. It adds further complexity.
Now let’s see how these specifics influence the modeling:
Recursion due to no-tail-forking. In order to bind the proposer to a QC of the previous view, timeout messages contain information about votes. Thus, the data type of a timeout certificate contains a tip (the highest proposal it voted for), and a tip type contains a timeout certificate. This is a recursion at the level of types; in real protocol messages, there is no unbounded recursion. Still, Quint does not support recursion (for historical reasons, and we are reconsidering this design decision on a regular basis), and we need to code around that. We have done similar things in the past for Leftcurve, but this involves some complexity in encoding.
Complex data types and a lot of state. Let’s consider timeout certificates TC. They are a data structure that proves that a quorum of processes have timed out in a certain view, together with information about previous votes by these processes:
type TC = {
view: int,
tip_views: Address -> int,
high_tip: Option[Tip],
qc_views: Address -> int,
high_qc: Option[QC],
sigma: Signature,
c: Set[TimeoutMsgAux],
}So we see that each timeout certificate contains maps of validator (Address) to views. As well as an optional quorum certificate,
type QC = {
view: int,
block_hash: int,
proposal_id: ProposalID,
sigma: Signature, // aggregated signature
c: Set[VoteMsg]
}Which itself contains a set of vote messages. So we have to maintain quite some state which can be present in messages sent over the network as well as within the local state of the validators, which contains
last_tc: Option[TC],
last_qc: Option[QC],So it is not hard to see that the state is huge. Indeed for model checking there is close to no hope without abstractions and refinements that would require a lot of human expertise and time. However, the Quint simulator brings great value even for such specifications, as we will see below. To do so, we will need some techniques to deal with the size of the state just for reviewing.
For instance, try our REPL with
quint -r instance.qnt::instanceAnd call the init action. This brings the REPL to a state where the protocol has already run for 4 views. The REPL outputs the new state, which requires close to 7000 lines! So filtering all this information will be key for effective debugging.
Optimizations and multiple paths to commits. The “upon” statements for proposal messages, votes, quorum certificates and timeout messages all contain a path to committing a block. For instance, as a quorum certificate is a part of a timeout message, this certificate can potentially be used to decide on a block if due to asynchrony the validator hasn’t received the votes in the certificate over a more standard path before receiving the timeout message. This is an optimization in the algorithm. At the same time, all these optimizations add complexity to the code and the model.
Side effects in pseudo-code. Take a look at the pseudo code in the paper. The code accumulates side effects, like changing state and sending/broadcasting messages. Algorithm 1’s “upon blocks” are sequences of (guarded) function calls, where these side effects pile up. At the same time, it makes sense to react to a vote in a single action, as interleaving with other processes does not add meaningful behaviors and we want to keep simulation runs short. So we have to collect side effects during the execution of a function, and apply all of them after the function is done in the action layer. This is a case where the formalization revealed a structural pattern in the pseudo-code that is easy to miss when reading it informally. After all, pseudo-code gives you infinite freedom, while a formal specification requires you to stick to a structure.
Message-by-message semantics in pseudo code. The paper uses message-by-message semantics, which results in very long simulation runs. For instance, in our recent blog post we mentioned that due to this, it takes 500 steps to reach a situation where a reproposal happens.
More than one protocol. As is typical for consensus engines, several subproblems need to be solved, e.g.,
- voting based on quorums to ensure safety,
- synchronizing processes to ensure that processes wait long enough so that voting can terminate, to ensure liveness, or
- recovering a block in case we learn that it has been decided on, that is block recovery, to make the actual data available (instead of just the hashes typically contained in the votes).
For analysis, it would be great if these subproblems were solved by isolated components that could be analyzed independently. In practical systems, such a separation is often not effective. In MonadBFT, for instance, the pacemaker that ensures liveness is not cleanly separated from voting. The practical consideration is that when a timeout occurs, a timeout should be signaled to the other participants and voting information should be broadcast. Doing this in two separate messages would add extra overhead and complicate the implementation (what if one of the two messages gets lost?). As a result, timeout messages carry certificates, which means the pacemaker has to know about the current voting state. So these protocols need to be analyzed together.
Key Techniques to Tame MonadBFT
Each aspect discussed in the previous section adds complexity to the protocol. This translates into a very large state space and many branches in the model: multiple paths to commit a block, an intricate recovery procedure, optimizations layered on top, and Byzantine behavior that can combine all of the above in adversarial ways. Left unchecked, the state space explodes before the simulator has a chance to find anything interesting. This section describes the main techniques we developed to bring the protocol within reach.
Unfolding Recursion
MonadBFT’s type definitions contain a subtle recursion. The paper defines a tip as ⟨view, proposal_id, block_hash, σ, tc, nec⟩, where the tc field is a full timeout certificate. A TC in turn contains a high_tip field of type Tip. This mutual reference is natural in the paper: the chain of historical certificates is conceptually unbounded, with each tip pointing to the TC that justified its view, which in turn points to the highest tip from the previous timeout round, and so on. Quint does not support recursive types, so we needed to encode this structure without changing the semantics.
Our solution was to unfold the recursion into a list. Instead of a Tip holding a TC that holds a Tip and so on, we replaced the tc field in Tip with a tc_as_chain field of type List[TCTipPair], where each entry holds a TCData and an optional TipData. These are stripped-down versions of TC and Tip that reference each other only through their position in the list rather than through nested types:
type Tip = {
view: int,
proposal_id: ProposalID,
block_header: BlockHeader,
sigma: Signature,
tc_as_chain: List[TCTipPair], // replaces the recursive tc field
nec: Option[NEC],
}The head of the list corresponds to the most recent TC, and each subsequent entry extends the chain toward older history. Validation mirrors this structure. The paper’s recursive ValidTip function, which calls ValidTC which calls ValidTip again, is replaced by valid_fresh_tip calling valid_tc_as_chain, which iterates over the list and validates each link using valid_tip_data, a non-recursive variant of the tip validator. The iteration does the work that recursion would have done in the paper.
Every Step Should Count
Our primary verification technique is simulation: we run the Quint simulator for days, exploring tens of millions of traces with up to 80 steps, and check that invariants and lemmas are never violated. The simulator explores execution traces step by step, so trace length directly determines how far into the protocol it can see. A trace that wastes 50 steps on internal bookkeeping before a single block is committed leaves almost no budget for the interesting multi-view scenarios where safety violations tend to live. Two complementary techniques kept our step count focused on what matters.
The first is the message soup design pattern from Choreo, Quint’s choreography layer (described in depth in a previous blog post). In a naive encoding of a distributed protocol, each message arrival is modeled individually: a validator receives one message, updates its local state, and the scheduler picks the next step. Most of these steps are uninteresting — they just accumulate messages without triggering anything meaningful. The message soup pattern eliminates this overhead. Instead of having actions enabled by a single message, actions are enabled only if a quorum threshold is reached. All the intermediate states where some messages have arrived (but not enough to have a real effect) are skipped entirely.
In MonadBFT, which is structured around quorum-driven events (vote quorums forming QCs, timeout quorums forming TCs), this maps naturally onto the protocol: each certificate formation becomes one atomic transition rather than a series of incremental steps, and the simulator reaches interesting multi-view scenarios in far fewer steps. For most message types the translation was indeed straightforward, but certain parts of the protocol required non-trivial adjustments. Vote handling, for example, carries very little per-message logic, so collapsing individual vote arrivals into a single quorum transition was mechanical. Timeout messages were a different matter. Each timeout handler does substantial work: it syncs the validator’s view, may commit some blocks and even send block proposals. Collapsing all of that into a single transition required rethinking how the handler was structured.
This tension led us to maintain two complementary variants of the specification. The message-by-message variant keeps the imperative structure of the pseudocode intact: each timeout message is processed individually as it arrives, and the quorum threshold is checked step by step. The quorum variant applies the message soup design pattern more aggressively: a separate listener fires only when a quorum of timeouts is available, delivering them atomically. This skips all intermediate states — no world where one of three timeout messages has been processed but not the other two — and shrinks the state space substantially, at the cost of diverging from the pseudocode’s structure. For simulations where covering more views per trace matters more than per-message fidelity, the quorum variant is the right tool.
The second technique is abstracting sub-protocols. In the case a sub-protocol’s internals are not the primary focus of the analysis, you can replace it with an atomic action that captures only the outcome. This is a compromise: you lose fidelity to the full protocol, but gain tractability. We applied this to two sub-protocols in MonadBFT. The first is the ancestor fetching protocol, triggered when a validator commits or speculatively commits a block and needs to retrieve its ancestors: we model this as an atomic lookup. The second, and more involved, is block recovery. Before a leader can repropose a block it does not have locally, it must recover it from the network. We replaced this with an abstraction that tracks which blocks each process holds locally. When a process is about to repropose a block, it checks this set: if a threshold of correct processes holds the block, recovery is guaranteed to succeed; if fewer do, the outcome is non-deterministic, either succeeding or returning a Non-Endorsement Certificate (NEC) indicating the block is provably unavailable. In both cases, recovery is a single atomic action.
Getting the block recovery abstraction right took some work. Our first version was too permissive, and the simulator found spurious violations of Lemma 7 as a direct consequence. After several iterations and discussions with the Category Labs team, we converged on a version that faithfully captures the protocol logic while keeping step counts manageable. The broader lesson is simple: for layered protocols, the abstraction boundary matters. Import too much complexity from the layer below and the model becomes intractable; abstract too loosely and you get spurious violations that obscure real ones.
From Violation to Root Cause
Debugging a Quint specification for a protocol this size is its own engineering challenge. By “debugging”, we mean figuring out the root cause of a violation. There can be several root causes, ranging from a too permissive abstraction (mentioned above), a wrong statement of an invariant, or an actual mistake in the protocol encoding, etc. In the case where Quint finds a problem, it will return an example trace that shows the behavior that led to the problem. However, due to the size of the state of MonadBFT, we could not just look at the trace, but needed tools to support analyzing traces. We encountered two distinct categories of problems, each requiring a different approach. The workflow described below reflects how we worked through the project; as a direct result of the friction we encountered, Quint’s runtime error reporting has since improved significantly (more on that in the last section).
Invariant violations are the easier case, because the simulator tells you which property failed. Our workflow here was to first write a displayer, a Choreo library construct that lets you print precisely the fragment of state that matters for the property you are debugging (and filter out the rest). For example, Lemma 5 states that no two correct validators vote for conflicting blocks in the same view. If that lemma is violated, you do not need to see the full protocol state. You write a displayer that prints, for each validator, the view it is in and the block it has voted for. With that output in hand, the violation is usually self-evident: you can see at a glance that two validators are in the same view with different votes, and trace backwards through the log to find where their states diverged. With the displayer in place, we would run the simulator and, when a violation trace was found, use the printed log generated by the displayer to understand what sequence of events led there. We would then retrieve the seed of the failing run to replay it deterministically, and translate the trace into a run, a hand-written scenario in Quint, to explore it step by step in the REPL until the root cause was clear.
Runtime errors are harder. A runtime error means, for instance, that Quint hit an undefined operation (typically an unwrap() of a None value or a get() of an absent map key), and at the time of this project the error message gave almost no information about where in the execution it happened or what the state looked like: no seed, no call hierarchy, no state snapshot. In fact the challenges in this project motivated us to improve error messages for runtime errors, and recent Quint releases solve the problems discussed here.
Still, during the project we had to deal with it. The goal of our approach was to first bypass the crash so the simulator could keep running and produce a trace. To do that, we would comment out pieces of code to bypass the crash and rerun, gradually narrowing down the location until we had isolated the problematic section. Once we had identified it, we would write a small invariant that encodes the condition that would have triggered the crash, without actually crashing. The simulator can then violate that invariant and hand us a concrete trace leading up to the problematic state, turning an opaque runtime crash into an ordinary invariant violation that we could inspect with a displayer, a seed, and the REPL. We would also use q::debug to inspect intermediate values at the relevant point in the trace.
The diagram below shows the full flow.
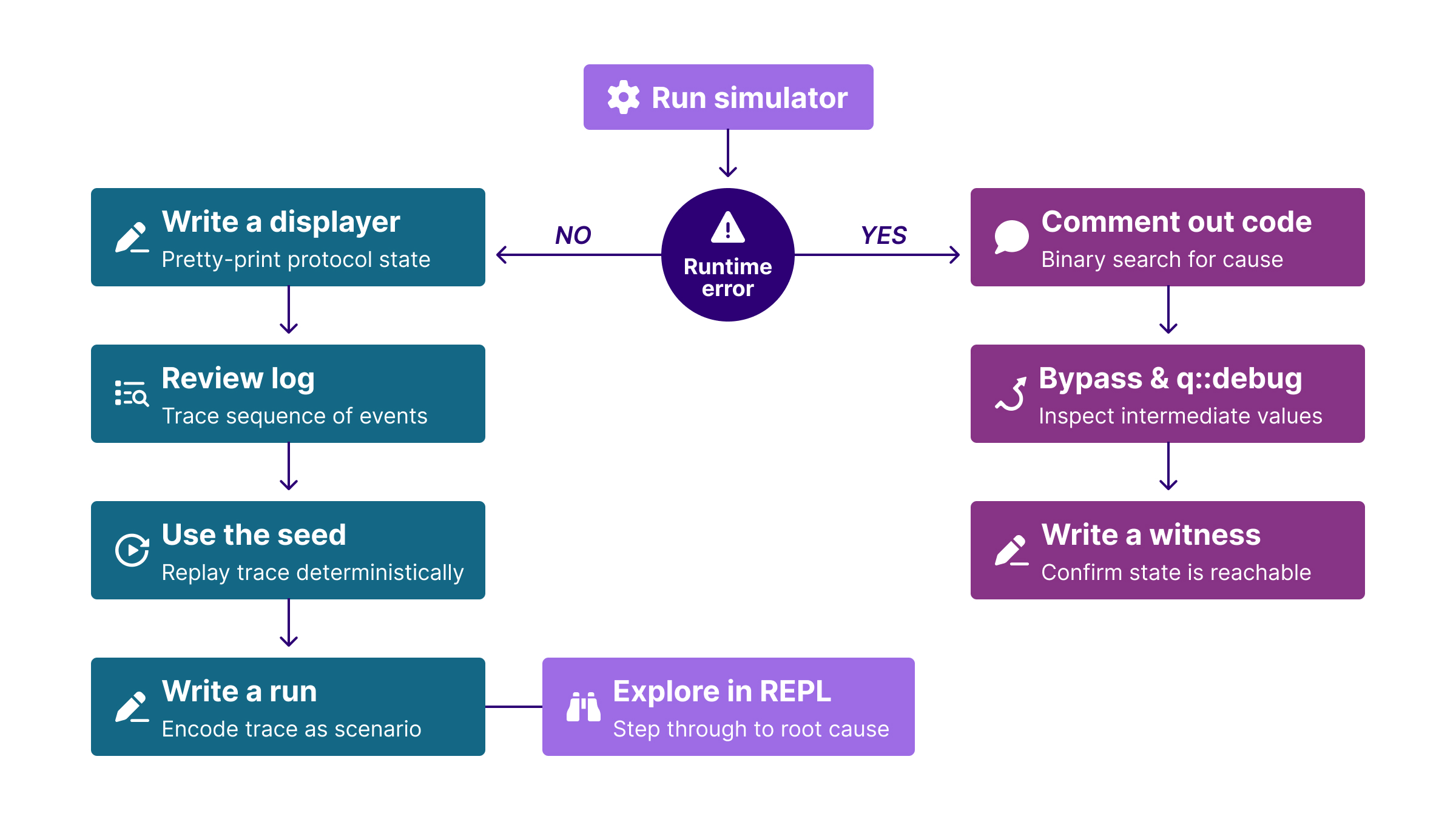
This workflow has helped us not only to debug our specification but also to identify several real issues, all of which we discuss in the Results section.
Don’t Just Check the Theorems
In formal verification efforts it seems quite natural to target the top-level theorems: safety and liveness. For MonadBFT, we encoded and checked not just the main safety theorems but all the supporting safety lemmas as separate Quint invariants. These cover agreement (Lemmas 1 through 8) and tail-forking resistance.
This turned out to be one of the most productive decisions in the project, for two complementary reasons.
From the simulator’s perspective, lemmas are tighter invariants: they constrain smaller, more specific fragments of behavior. A simulator checking Lemma 5 (roughly: “no two correct validators vote for conflicting blocks in the same view”) does not need to produce a full commit to find a violation; a much shorter trace suffices. Checking the full safety theorem directly would require the simulator to navigate through two committed blocks on conflicting chains before it could flag anything, which is a much rarer event in a random walk.
From a debugging perspective, lemma violations are often easier to work through than theorem violations. Take Lemma 7 as an example, which states that if a proposal gets enough support from correct validators and the leader did not equivocate, then any valid proposal in any subsequent view must build on top of it. A violation therefore points you directly at a concrete mismatch in that relationship, which is a much more focused starting point than a raw agreement violation, even if the latter is not conceptually complex in itself. In our case, this pointed us immediately to a bug in the extend definition that we describe in the last section.
There is an important caveat: a lemma may be violated without the overall theorem being broken. The cause could be an ambiguity in the definitions, a part of the protocol that is left unspecified, or even a lemma statement that is simply stronger than what the proof of the theorem actually requires. Distinguishing between these cases requires careful human judgment, but a lemma violation gives you a precise starting point for that judgment, which is far better than starting from nothing. We encountered lemma violations several times, which were signals to revisit the paper’s definitions rather than evidence of a true safety bug.
Teaching Quint to Misbehave
The guarantees a Byzantine fault-tolerant protocol provides are only meaningful relative to the Byzantine behaviors the model considers. When modeling Byzantine actors in a formal specification, one option is to preload the message buffer with Byzantine messages: the adversary decides at the start of the execution which messages to send, which equivocations to make, and so on. This is particularly effective if you can separate different views (or heights) or you have a one-shot consensus algorithm from the beginning, because the number of well-formed Byzantine messages is still quite limited. One big advantage is that you don’t need Byzantine actions (that makes simulation traces longer).
The challenge with MonadBFT is that after a couple of views, messages are filtered out if the historical data encoded in them deviates from the view of the correct processes. As a result, for Byzantine messages to be potentially dangerous, they need to contain some correct information mixed with some adversarial data. This cannot be preloaded effectively as we would need to preview decisions of later views.
We took the interactive approach instead. Byzantine actors in our model are full participants in every step of the execution: at each point, the scheduler can choose to have a Byzantine validator take one of several distinct adversarial actions, interleaved arbitrarily with honest behavior. These cover a range of attack strategies, including equivocating proposals, double voting, embedding unavailable blocks in timeout messages, and injecting conflicting votes through timeout messages. The Byzantine actions have access to the global state, and can add faulty messages based on the current global state in the simulation, for instance, point to previously sent quorum certificates.
The interactive model is more useful for simulation: because Byzantine actions are available at every step, the simulator can discover adversarial patterns that a preloaded model would likely miss. The tradeoff is a larger step count per trace, since a Byzantine action is an additional choice at each step, but this is largely offset by the step-minimization techniques described above.
The Byzantine behavior set was not designed all at once. We started with the simpler actions and added more sophisticated ones as the simulator revealed new attack surfaces. Modeling Byzantine behavior in this incremental, feedback-driven way is itself a technique worth emphasizing: rather than trying to enumerate all possible adversarial behaviors upfront, let the simulator guide you.
Note that we are operating here in a grey area of theoretical definitions. Byzantine faults are typically understood as pure non-determinism: they may send any kind of messages. This contrasts with another definition: the algorithms assume digital signatures, which implies Byzantine nodes cannot send messages that contain data that looks like it was signed by a correct process if the correct process hasn’t done so. So we need to deal with some restricted form of non-determinism which allows us to forward messages sent by a correct process in the past. Using Byzantine actions that have access to the global state allows us to capture this.
Results of the Exploration
We ran extended simulations, days of wall-clock time, over both variants of the specification (the message-by-message variant for fidelity and the quorum variant for deeper coverage), interleaving Byzantine behavior and checking all safety lemmas alongside both main safety theorems. We did not find any critical safety or liveness issues in the current version of the protocol.
What we did find was a set of inconsistencies among the paper’s definitions, pseudocode, and proofs. These are precisely the kinds of issues that are invisible to a pen-and-paper review but surface immediately when you have an executable model that can explore thousands of interleavings. Here is a summary of the main findings.
The extend definition. We found a mistake in the definition of the extend relation between blocks. The definition in the paper, as written, was inconsistent with how extend is used in the safety proof. We discovered the problem when the simulator reported a violation of Lemma 7 that was based on the buggy definition. The Category Labs team proposed an alternative definition; we added it to the model and confirmed via simulation that the violation of the lemma was spurious and disappeared with the proper definition of extend.
Commitment behavior. The paper does not specify what happens when a node commits a block, which implicitly may imply committing a chain of blocks. This unspecified region caused a violation of Theorem 1. After agreeing on a concrete interpretation with the Category Labs team, we added the logic to the model and confirmed via simulation that Theorem 1 holds under that interpretation.
Cached proposals. The paper assumes that whenever a validator votes for a proposal, it caches it locally, which is important for tail-forking resistance: if sufficiently many correct validators voted for a proposal, their caches collectively guarantee that the corresponding block is recoverable. What the paper does not make explicit is whether a proposal voted for via a timeout message also ends up in the cache. After clarifying with the Category Labs team that it should, we updated the model accordingly.
TC vector initialization. Algorithm 5, line 53 checks whether an entry in the tips vector is not bottom (⊥). But the way a TC is constructed, following Algorithm 3 line 20, entries are initialized to 0, not ⊥, which means the check always passes and can never filter anything out. We observed that some TCs constructed following the protocol were not passing ValidTC. After discussion, the Category Labs team agreed that the vector should be initialized to ⊥.
Double voting via timeout. The most operationally significant finding was that to ensure safety, a validator must not accept more than one timeout message per sender per view. The pseudocode did not explicitly state this requirement, so our initial model also did not enforce this. Without this constraint, a Byzantine validator could insert conflicting votes via two distinct timeout messages in the same view, and a correct validator accumulating timeout quorums would process both. Running the simulator on this too permissive model led to a spurious violation of a safety property. Adding an explicit “at most one timeout message per sender per view” check to the model eliminated the violation, matching the real implementation of the protocol.
Alongside the long-running simulations, we also wrote a set of tests, much as one would when implementing a protocol: covering the happy path, the timeout recovery flow, and the various edge cases involving crashed leaders and slow validators. This is a natural part of building confidence in a model, and it has a useful side effect. Each test is a Quint run that follows a specific sequence of actions step by step, so for the scenarios depicted in the paper’s diagrams, the corresponding run doubles as a mechanical check of the diagram itself. If the run succeeds, the depicted scenario is feasible in the model. If it fails, the diagram would contain an inconsistency with the pseudocode.
Conclusions
We set out to analyze MonadBFT using Quint, and in doing so developed a set of techniques for making a large, complex distributed protocol tractable for simulation-based verification. The message soup pattern keeps traces short by collapsing quorum thresholds into atomic transitions. Abstracting layered sub-protocols trades completeness for tractability. Encoding lemmas alongside theorems gives the simulator tighter targets and humans more focused starting points for debugging. Modeling Byzantine behavior interactively and incrementally lets the simulator surface attack patterns a preloaded model would miss. And writing scenario tests validates the model while providing a mechanical check of the paper’s diagrams as a by-product.
None of these techniques are specific to MonadBFT. Any distributed protocol with quorum logic, layered sub-protocols, and a proof structure built from intermediate lemmas can benefit from the same approach. The combination of a precise executable model and a fast simulator turns the kind of inconsistencies that survive pen-and-paper review into concrete, inspectable traces.
Working on a protocol at this scale also fed back into Quint itself. The most impactful improvement was the adoption of the Rust simulator as the default backend, which runs roughly an order of magnitude faster than the previous TypeScript simulator. For MonadBFT this was the difference between exploring thousands of traces per minute and a few hundred, and that extra coverage is what allowed us to find the subtle violations described above. Runtime error reporting also improved significantly. Both improvements and more are now available to anyone using the latest version of the Quint tools.